Consensus Monte Carlo for Random Subsets using Shared Anchors
Abstract
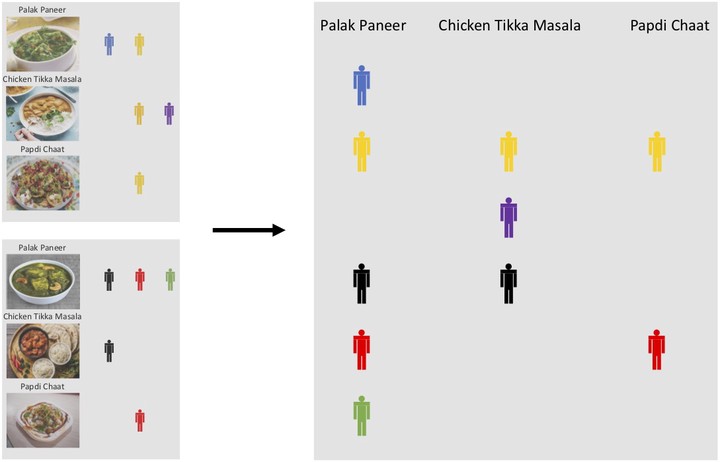
We present a consensus Monte Carlo algorithm that scales existing Bayesian non- parametric models for clustering and feature allocation to big data. The algorithm is valid for any prior on random subsets such as partitions and latent feature allocation, under essentially any sampling model. Motivated by three case studies, we focus on clustering induced by a Dirichlet process mixture sampling model, inference under an Indian buffet process prior with a binomial sampling model, and with a categorical sampling model. We assess the proposed algorithm with simulation studies and show results for inference with three datasets, an MNIST image dataset, a dataset of pancreatic cancer mutations, and a large set of electronic health records (EHR). Supplementary materials for this article are available online.